
Every business decision today rests on data but raw data, sitting unorganized across spreadsheets, databases, and disconnected systems, doesn’t help anyone make a decision. It has to be collected, cleaned, validated, and turned into something usable first. Data processing solutions make that transformation and it is silently one of the most crucial operational activities within modern firms, no matter the industry.
What Are Data Processing Solutions?
Data processing, at its foundation, is just the act of taking raw, unstructured data and turning it into something clean, organised and usable. Raw data, like a retail chain’s point-of-sale logs, a hospital’s patient intake forms or a bank’s transaction records, is often too messy and voluminous on its own for a human to act on directly. Data Processing Solutions are the systems, software and workflows that take that raw input and turn it into structured datasets, reports and insights that people and other systems can actually use.
This isn’t a single tool so much as a pipeline: data enters, moves through several stages of refinement, and exits as something decision ready.
Why Businesses Need Data Processing Solutions
The need comes down to volume and speed. As companies grow, the amount of data they generate grows faster than their ability to manually handle it. A business processing a few hundred customer records a month can get away with spreadsheets. A business processing a few hundred thousand records a day cannot. Without a structured way to process that data, errors creep in, decisions slow down, and opportunities get missed simply because the information needed to act on them was never extracted from the noise in time.
How Data Processing Solutions Work
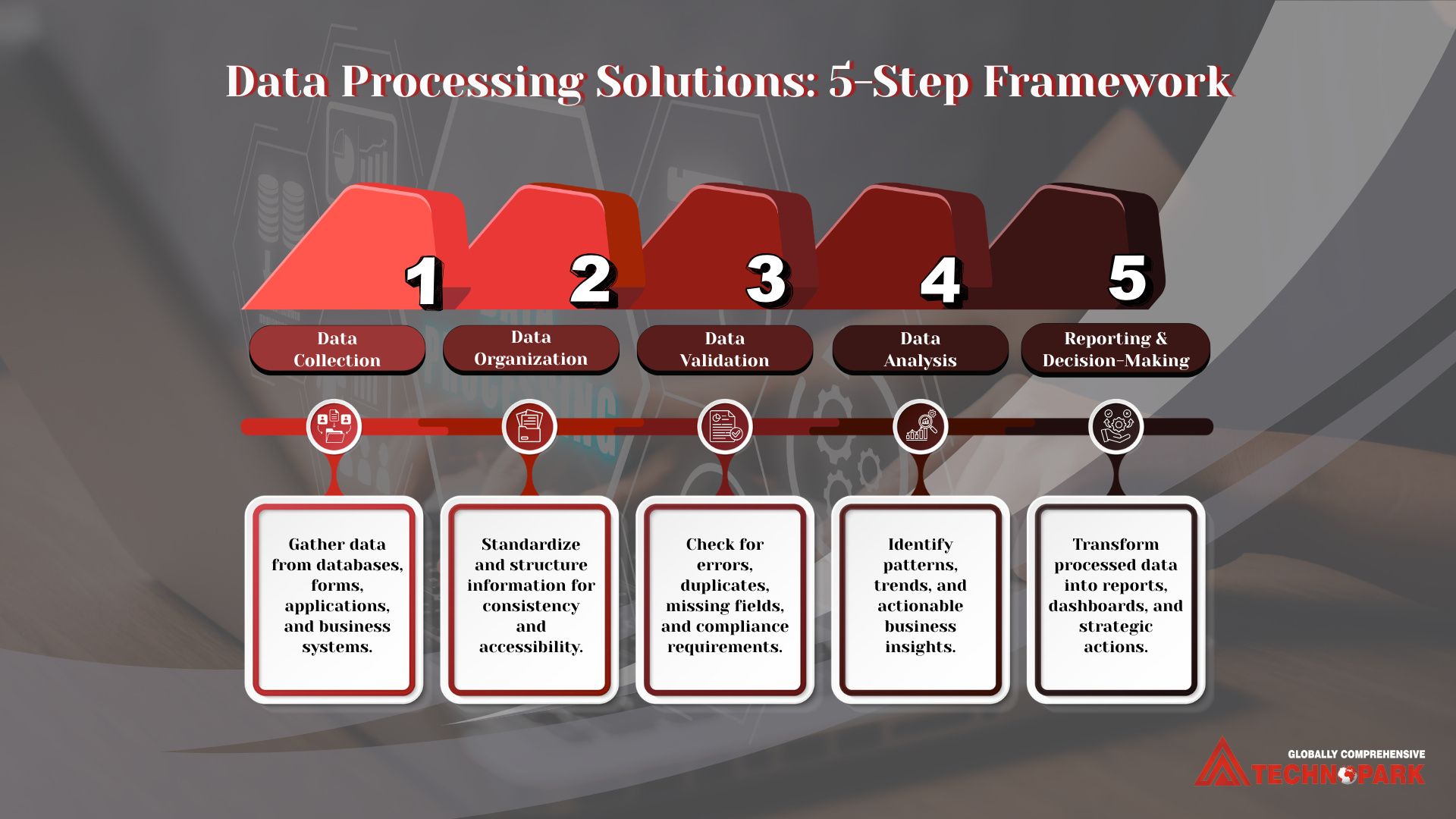
Most data processing solutions follow a similar five-stage pipeline, regardless of the industry or the specific software involved.
Data Collection
The initial phase in the pipeline is to collect data from sources such as transactional systems, IoT devices, customer forms, third-party APIs, or legacy databases. The collection stage is where data processing solutions establish connections to all the places information lives, often consolidating dozens of disparate sources into a single intake point.
Data Organization
Once collected, data rarely arrives in a consistent format. One source might log dates as MM/DD/YYYY, another as a Unix timestamp. The organization stage standardizes formats, structures, and naming conventions, allowing teams to compare and combine data reliably.
Data Validation
This is the quality-control stage. Validation checks for duplicates, missing fields, outliers, and inconsistencies flagging or correcting records before they have a chance to skew an analysis or trigger an incorrect business decision.
Data Analysis
With clean, organized, validated data in hand, analysis tools and techniques, statistical models, machine learning algorithms, or simpler aggregation and trend logic extract patterns and insights. This is where data starts to answer actual business questions: which customers are likely to churn, where inventory is running low, which transactions look fraudulent.
Reporting and Storage
Finally, the processed data and the insights derived from the data are packaged into dashboards, reports or automated alerts and stored in a structured system, a data warehouse, BI platform or internal database where it is available for future use, audits or further analysis.
The Five-Step Data Processing Framework at a Glance
If you need the short version to present with a team or a stakeholder, the pipeline above may be boiled down to five steps: collect, organise, validate, analyse, report. Each step depends on the one before it skipping validation, for instance, means any analysis built on top of that data inherits its errors. Treat this as the one-line summary of the detailed breakdown above, useful for training materials or a quick internal reference, rather than a separate process.
Key Benefits of Data Processing Solutions
Improved Data Accuracy
Manual data handling is error-prone: a misplaced decimal, a duplicated row, a typo in a customer ID can all cascade into bad decisions. Automated validation rules catch the overwhelming majority of these issues before they reach a report or a downstream system.
Faster Decision-Making
When data moves automatically from collection to report, the lag between “something happened” and “someone knows about it” shrinks from days or weeks to minutes or hours. The pace quickens. The faster you know about a supply chain disruption or a spike in customer complaints, the faster you can react.
Enhanced Operational Efficiency
Teams that would have spent hours a week reconciling spreadsheets manually now can spend those hours on real analysis and decision making, not data janitorial work. The efficiency gain isn’t just about saving hours, it’s about freeing skilled people from low-value tasks.
Enhanced Compliance
Healthcare’s HIPAA, finance’s SOX and AML regulations, and data privacy legislation like GDPR all depend on data being handled consistently, with audit trails detailing the precise methods of data collection, validation, and storage. Ad hoc manual handling does not normally provide this traceability but structured data processing does.
Industries That Benefit from Data Processing Solutions
Healthcare
Patient records, lab results, billing codes, and insurance claims all need to be processed accurately and in compliance with HIPAA. In healthcare, data processing solutions tend to be focused on validation and security because mistakes here directly impact patient safety and legal liability.
Banking and Finance
Financial institutions process enormous volumes of transactions in real time, much of it scanned for fraud and anti-money-laundering compliance as it happens. Speed and accuracy are not optional; a late fraud alarm or a missed compliance check has immediate financial and regulatory impact.
Telecommunications
Telecom providers process call records, network usage data, and customer behavior at a scale that’s difficult to grasp billions of events daily across large carriers. The priority is usually around churn prediction and network optimization, both of which depend on processing usage data close to real time.
Technology
Software and SaaS companies employ user behaviour data, application logs, and product telemetry to make product decisions and find performance problems. Here data processing generally travels directly to product analytics tools and A/B testing frameworks
Real Estate
For real estate companies with large portfolios, structured processing of property data, market comparable, transaction histories and tenant records is useful. It is impossible to manually track lease terms, valuations and maintenance records across hundreds of properties without automation.
In-House vs Outsourced Data Processing: Making the Right Call
Most businesses eventually face a fork in the road: build the data processing capability internally, or bring in an outside provider. There’s no universally right answer; it depends on volume, budget, and how central data processing is to your competitive advantage.
When to Build an In-House Team
An in-house strategy often makes sense when data processing interfaces with proprietary systems, demands extensive subject knowledge that is hard to outsource, or the organization is large enough to support specialised staff and infrastructure. It requires an up-front investment in people and systems, but allows you full control over priorities, security and tools.
When Outsourcing Makes More Sense
Outsourcing is often the better option when data volumes are increasing more quickly than internal hiring can keep up with, when manual errors are becoming a regular pain point, or when the business needs the workflow efficiency gains from automation without the lead time of building a team from the ground up. It also works for businesses that want access to specialized expertise in machine learning, compliance, or the data idiosyncrasies of a particular industry without having to keep that expertise on staff full-time.
Cost Considerations
In-house teams carry fixed costs: salaries, software licenses, infrastructure, and ongoing training, regardless of how much data actually needs processing in a given month. Outsourced providers typically operate on variable, volume-based pricing, which can be cheaper at lower or fluctuating volumes but may become more expensive than an in-house team once volume is consistently high. The honest comparison requires modeling your actual data volume trajectory over the next two to three years, not just current costs.
Choosing a Data Processing Partner
If outsourcing looks like the right direction, the provider you choose matters as much as the decision to outsource itself.
What to Look For
Look for demonstrated experience in your specific industry. A provider skilled in retail data has different strengths than one built for healthcare compliance. Check what security certifications they hold, how transparent their validation and error-handling process is, and whether their reporting integrates with the BI or analytics tools you already use.
Questions to Ask Before You Commit
Before signing on, it’s worth asking what happens to your data if you switch providers later, how are errors caught and reported, what’s the actual turnaround time from data submission to usable output, and can they show you results from a business of similar size and industry. Vague answers to any of these are a warning sign.
Future Trends in Data Processing Solutions

AI-Powered Processing
Machine learning models are increasingly handling tasks that used to require manual review, flagging anomalies, classifying unstructured text, and even predicting where data quality issues are likely to occur before they happen. This is shifting data processing from purely reactive cleanup toward proactive quality management.
Cloud-Based Data Management
Cloud infrastructure has made it possible to scale data processing capacity up or down on demand, without the capital expense of on-premises servers. It also helps processing pipelines integrate data from multiple systems and locations.
Real-Time Analytics
The gap between “data is processed” and “data is analysed” is closing. Streaming data pipelines now allow some businesses to act on information within seconds of it being generated, rather than waiting for a nightly or weekly batch process particularly valuable in fraud detection, network monitoring, and live customer experience adjustments.
Building Smarter Data Operations
Data processing solutions have moved from a back-office convenience to a core operational requirement. The businesses getting the most value from their data aren’t necessarily the ones generating the most of it, they’re the ones that have built, or partnered for, a reliable pipeline to collect, organize, validate, analyse, and report on it consistently. Whether that pipeline lives in-house or with an outside partner depends on your volume, your budget, and how much that capability needs to stay close to the rest of your business but having one, in some form, is no longer optional for companies operating at scale.
Turn Data Into Better Decisions
Frequently Asked Questions
1. What are data processing solutions?
Data processing solutions convert raw data into organized, accurate, and usable information.
2. What is the difference between data processing and data analytics?
Data processing is preparing data, while analytics is analysing that data to provide insights and trends.
3. What industries use data processing solutions?
Healthcare, banking, telecommunications, technology and real estate are common industries that rely on data processing.
4. How much does outsourcing data processing cost?
The cost depends on the volume of data, its complexity and the business requirements.
5. When should businesses outsource data processing?
When data volumes grow, errors increase, or specialized expertise is needed.